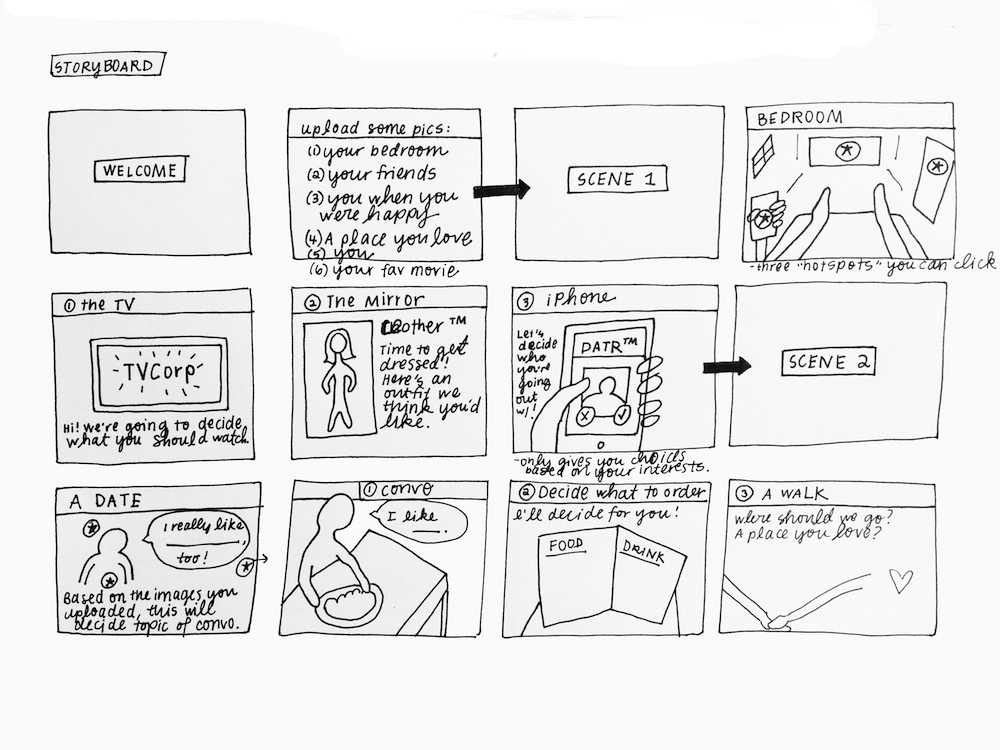
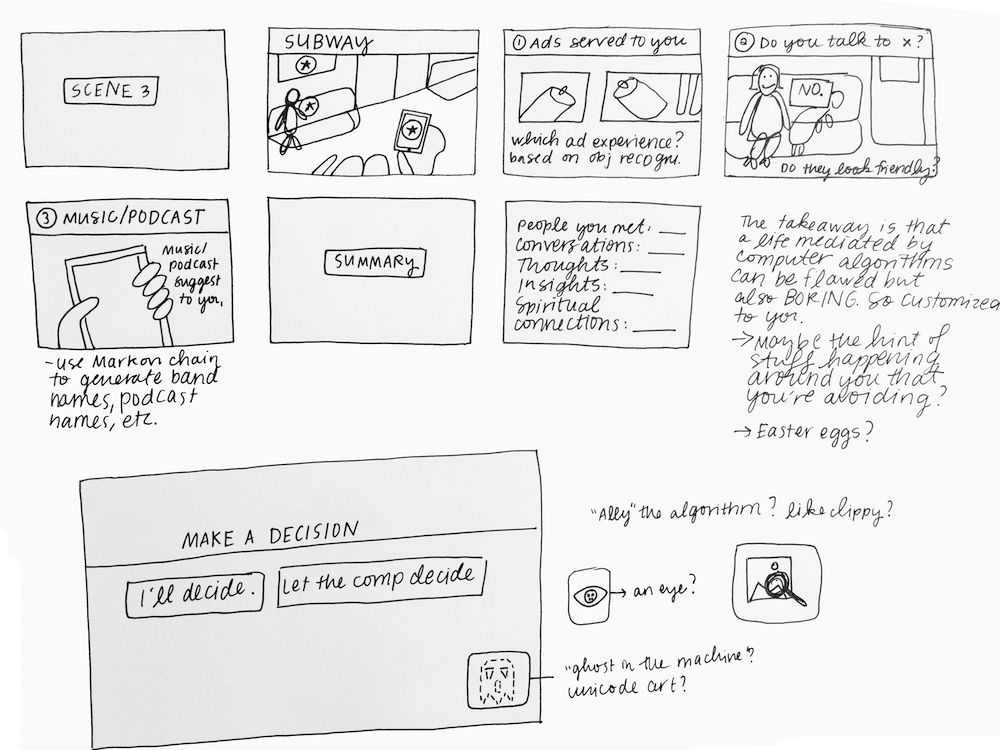
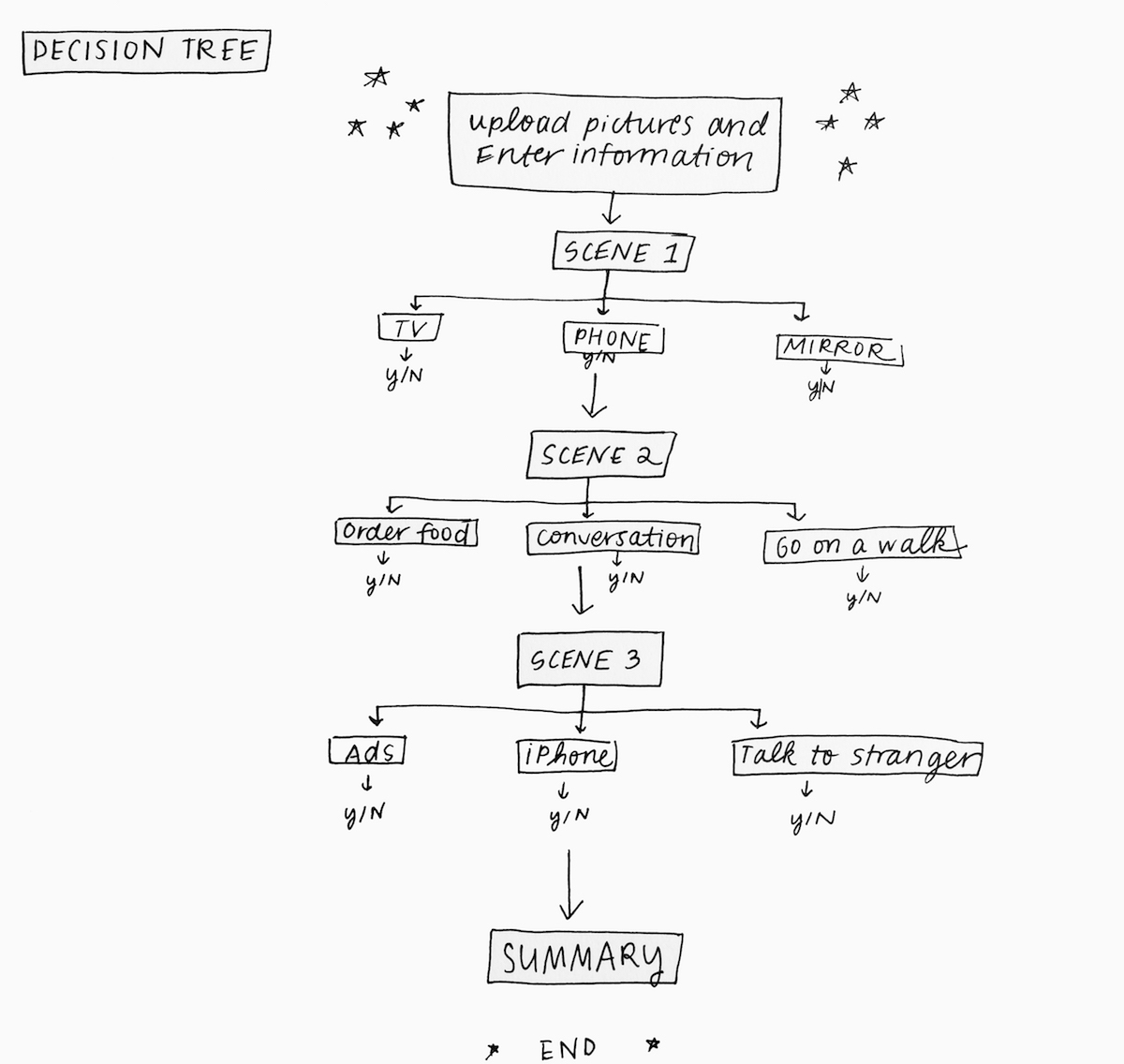
Since I wrote extensively about the user journey and narrative last week, I wanted to review some of the technical work I’ve been doing this week as I’ve attempted to get my deep learning framework (a tool for generating stories from images) up and running.
I started by following the installation & compilation steps outlined here for neural storyteller. The process makes use of skip-thought vectors, word embeddings, conditional neural language models, and style transfer. First, I installed dependencies, including NumPy, SciPy, Lasagne, Theano, and all their dependencies. Once I finish setting up the framework, I’ll be able to do the following:
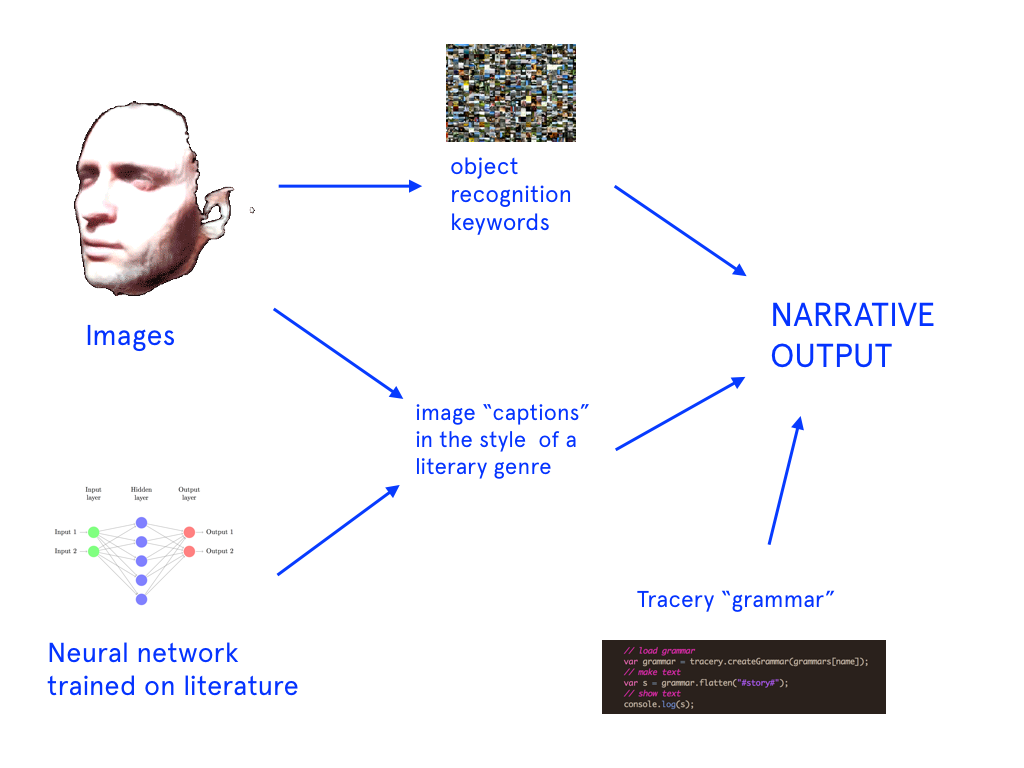
- Train a recurrent neural network (RNN) decoder on a genre of text (in this case, mystery novels). Each passage from the novel is mapped to a skip-thought vector. The RNN is conditioned on the skip-thought vector and aims to generate the story that it has encoded.
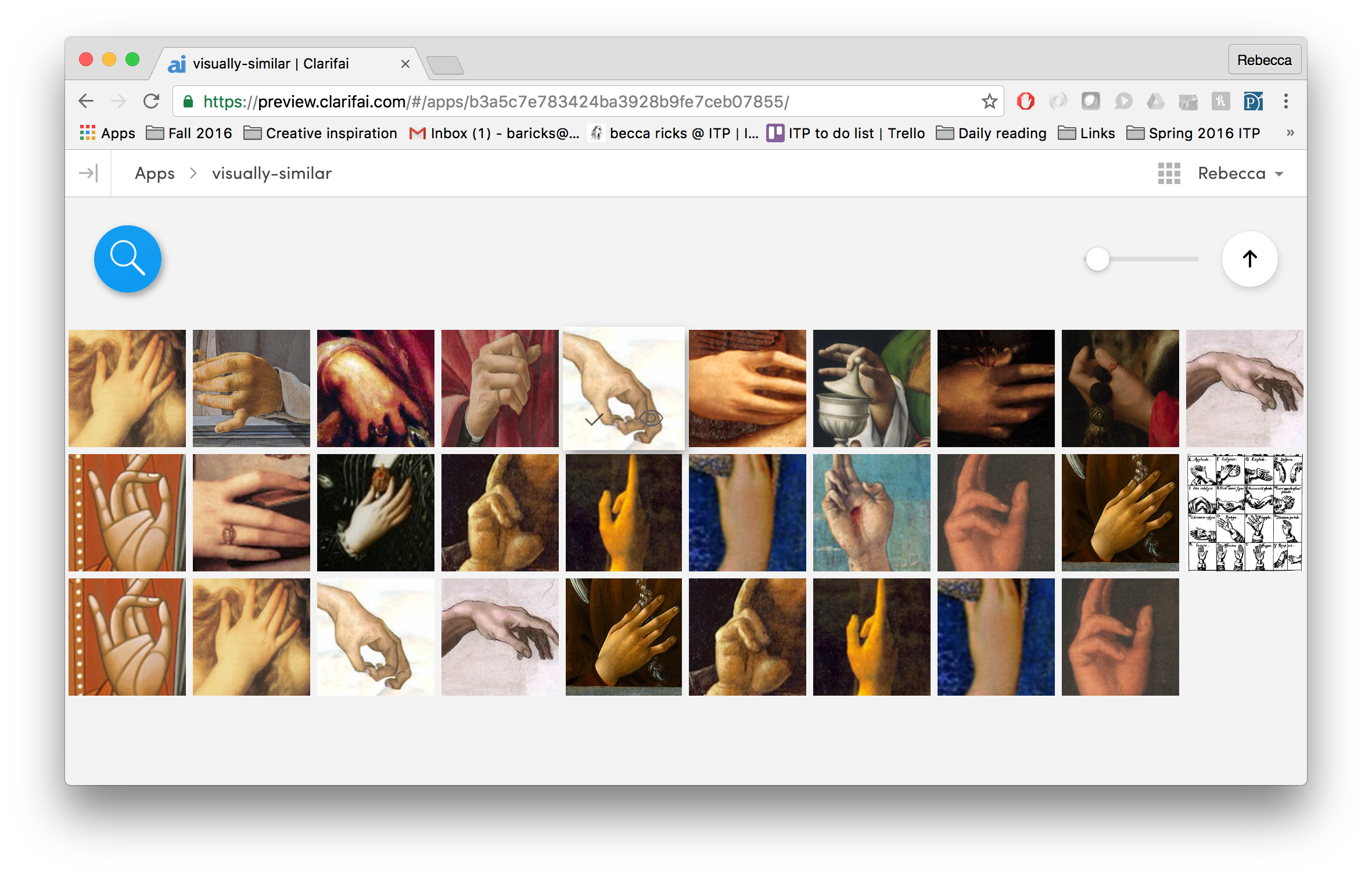
- While that’s happening, train a visual-semantic embedding between Microsoft’s COCO images and captions. In this model, captions and images are mapped to a common vector space. After training, I can embed new images and retrieve captions.
- After getting the models & the vectors, I’ll create a decoder that maps the image caption vectors to a text vector that I would then feed to the encoder to get the story.
- The three vectors would be as follows: an image caption x, a “caption style” vector c and a “book style” vector b. The encoder F would therefore look like this: F(x) = x – c + b. In short, it’s like saying “Let’s keep the idea of the caption, but replace the image caption with a story.” This is essentially the style transfer formula that I will be using in my project. In this scenario, c is obtained from the skip-thought vectors for Microsoft COCO training captions and b obtained from the skip-thought vectors for mystery novel passages.
So far I’ve successfully set up the frameworks for skip-thought vectors (pre-trained on romance novels) & Microsoft’s COCO vectors. Now, I’m in the middle of installing and compiling Caffe, a deep learning framework for captioning images. I feel like I’ve hit a bit of a wall in the compilation process. I’ve run these commands specified in the Makefile, which have succeeded:
make clean
make all
make runtests
make pycaffe
When I try to import caffe, however, I get an error stating that the module caffe doesn’t exist, which means that there was some error in the build/compilation process. I’ve been troubleshooting the build for over a week now. I’ve met with several teachers, adjuncts, and students to troubleshoot. Today, I finally decided to use an Ubuntu container for caffe called Docker (which came highly recommended from a number of other students). I’m optimistic that Docker will help control some of the Python dependency/version issues I keep running into.
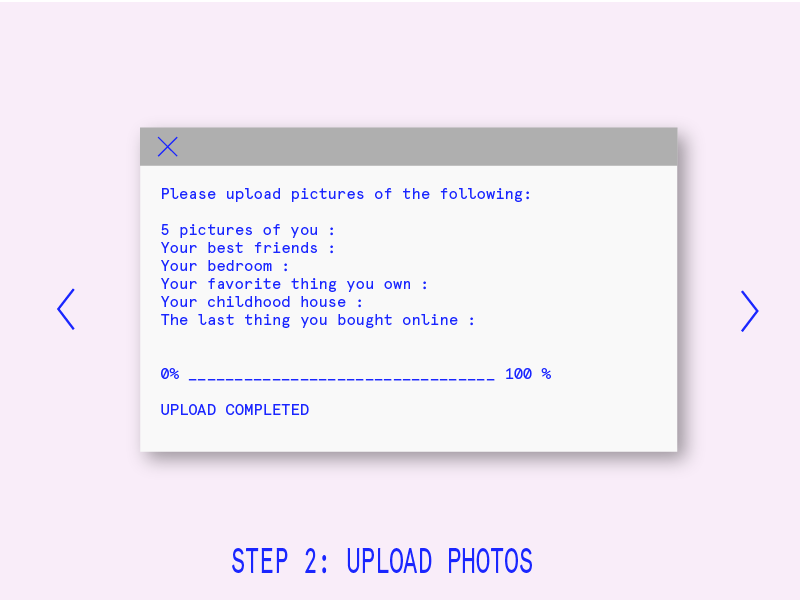
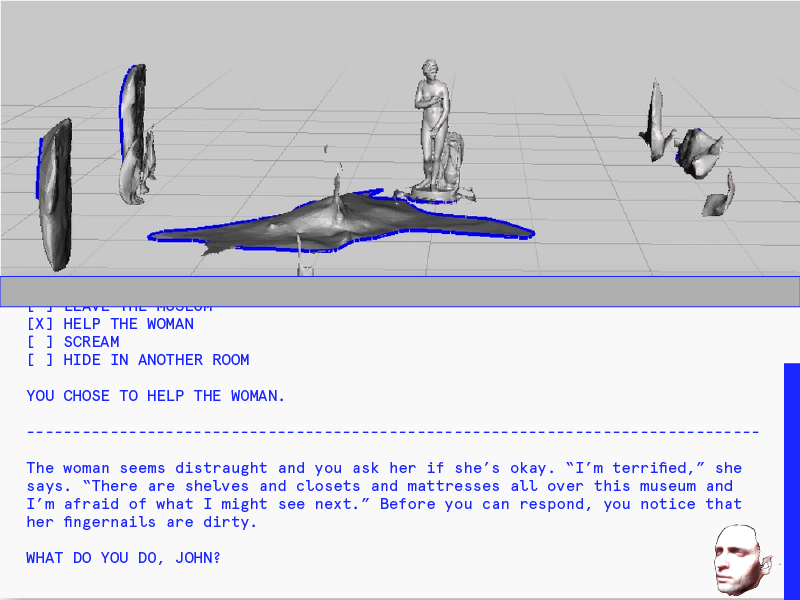
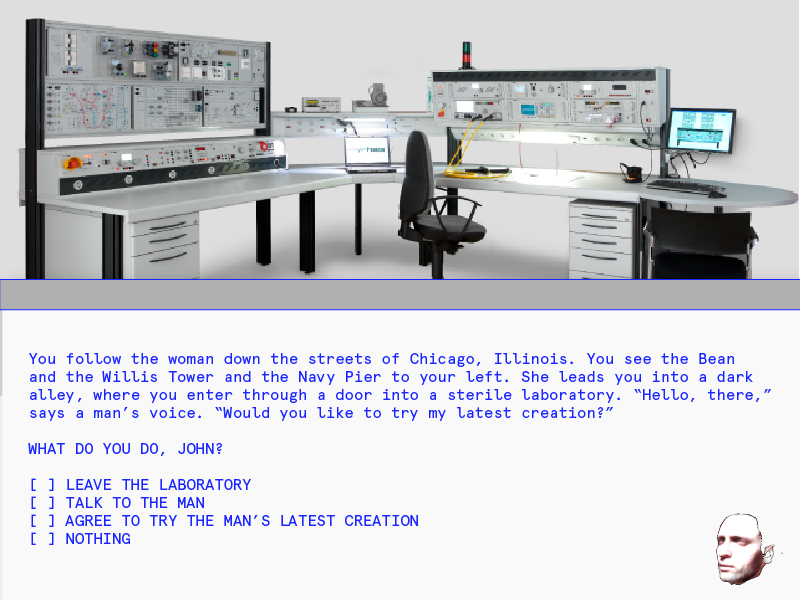
When I haven’t been working on the machine learning component of my project, I’ve started working on the website (running server-side, using node + express + gulp) where the game will live. I’ll be using this JQuery plugin that mimics the look and feel of a Terminal window.


























{kind=link}
{kind=link}