As mentioned last week, I’m exploring the idea of the algorithmic gaze vis-a-vis computer vision and machine learning tools. Specifically, I’m interested in how such algorithms describe and categorize images of people. I’d like to focus primarily as the human body as subject, starting with the traditional form of the portrait. What does a computer vision algorithm see what it looks at a human body? How does it categorize and identify parts of the body? When does the algorithm break? How are human assumptions baked into the way the computer sees us?
As mentioned last week, I’m interested in exploring the gaze as mediated through the computer. Lacan first introduced the concept of the gaze into Western philosophy, suggesting that a human’s subjectivity is determined by being observed, causing the person to experience themselves as an object that is seen. Lacan (and later Foucault) argues that we enjoy being subjectivized by the gaze of someone else: “Man, in effect, knows how to play with the mask as that beyond which there is the gaze. The screen is here the locus of mediation.”
The following ideas are variations on this theme, exploring the different capabilities of computer vision.
Project idea #1: Generative text based on image INPUT.
At its simplest, my project could be a poetic exploration of text produced by machine learning algorithms when it processes an image. This week I started working with several different tools for computer vision and image processing using machine learning. I’ve been checking out some Python tools, including SimpleCV and scikit. I also tested out the Clarifai API in JavaScript.
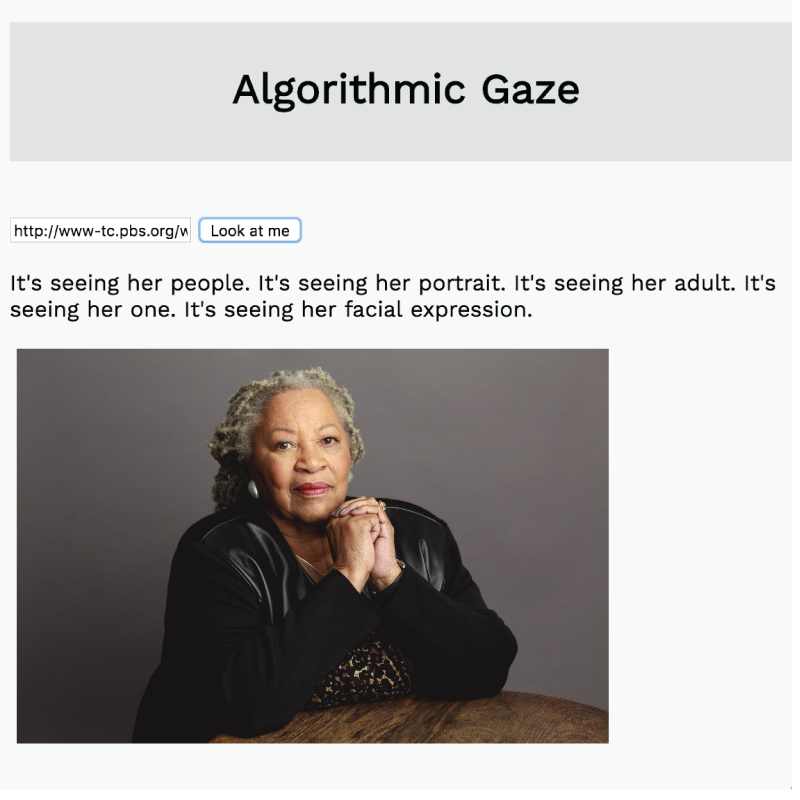
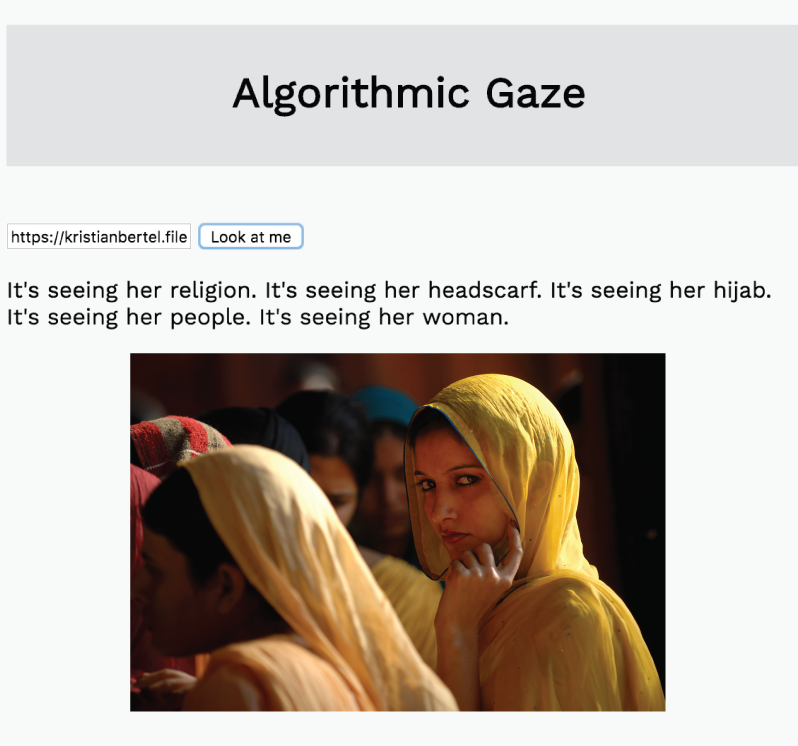
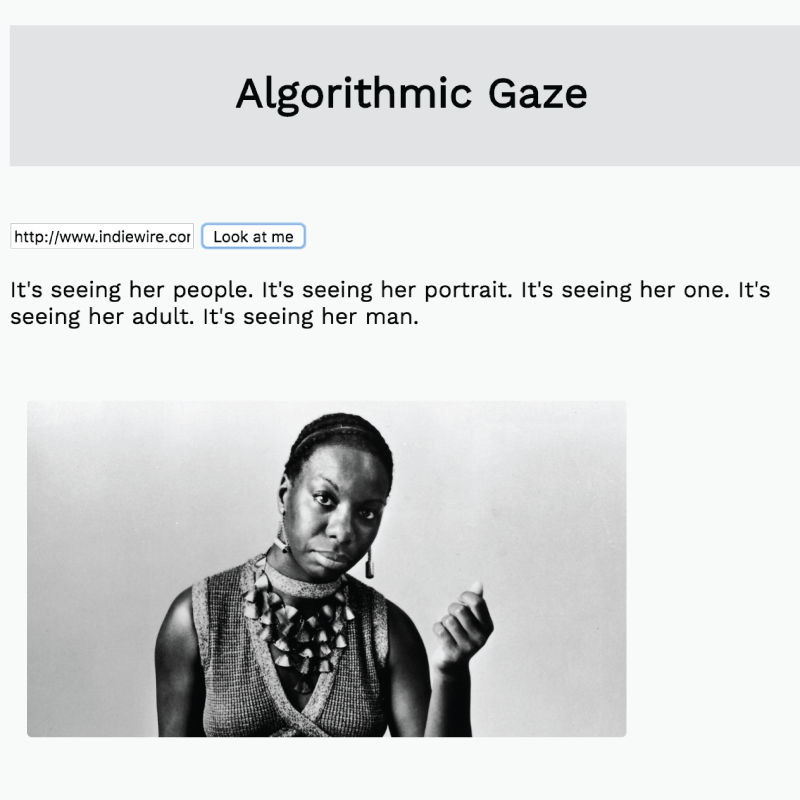
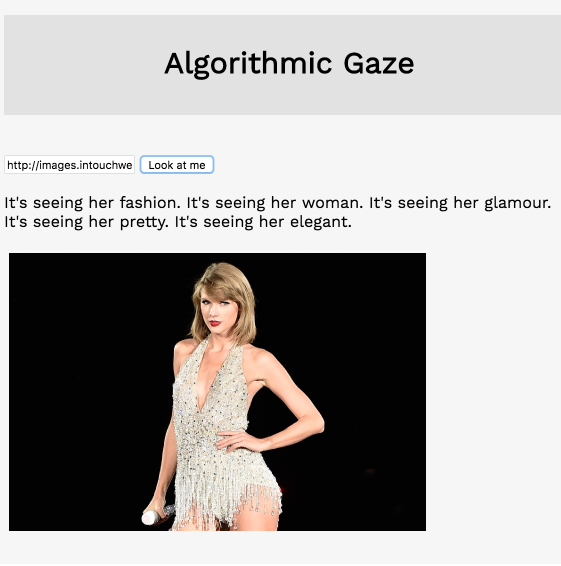
In the example below, I’ve taken the array of keywords generated by the Clarifai API and arranged them into sentences to give the description some rhythm.
Check out the live prototype here.
I used Clarifai’s image captioning endpoint in order to generate an array of keywords based on the images it’s seeing and then included the top 5 keywords in a simple description.
{kind=link}
You can find my repo code over here on Github.
PROJECT IDEA #2: IMAGE PAIRINGS OR CLUSTERS.
In the first project idea, I’m exploring which words an algorithm might use to describe a photo of a person. With this next idea, I’d be seeking to understand how a computer algorithm might categorize those images based on similarity. The user would input/access a large body of images and then the program would generate a cluster of related images or image pairs. Ideally the algorithm would take into account object recognition, facial recognition, composition, and context.
I was very much inspired by the work done in Tate’s most recent project Recognition, a machine learning AI that pairs photojournalism with British paintings from the Tate collection based on similarity and outputs something like this:

The result is a stunning side-by-side comparison of two images you might never have paired together. It’s the result of what happens when a neural net curates an art exhibition – not terribly far off from what a human curator might do. I’d love to riff on this idea, perhaps using the NYPL’s photo archive of portraits.
Another project that has been inspiring me lately was this clustering algorithm created by Mario Klingemann that groups together similar items:

I would love to come up with a way to categorize similar images according to content, style, and facial information – and then generate a beautiful cluster or grid of images grouped by those categories.
PROJECT IDEA #3: DISTORTED IMAGES.
A variation on the first project idea, I’d like to explore the object recognition capabilities of popular computer vision libraries by taking a portrait of a person and slowly, frame by frame, incrementally distorting the image until it’s no longer recognized by the algorithm. The idea here is to test the limits of what computers can see and identify.
I’m taking my cues from the project Flower, in which the artist distorted stock images of flowers and ran them through Google’s Cloud Vision API to see how far they could morph a picture while still keeping it recognizable as a flower by computer vision algorithms. It’s essentially a way to determine the algorithm’s recognizable range of distortion (as well as human’s).


I’m interested testing the boundaries of such algorithms and seeing where their breakpoints are when it comes to the human face.*
*After writing this post, I found an art installation Unseen Portraits that did what I’m describing – distorted images of faces in order to challenge face recognition algorithms. I definitely want to continue investigating this idea.

PROJECT IDEA #4: interpreting BODY GESTURES IN paintings.
Finally, I want to return to my idea I started with last week, which was focused on the interpretation of individual human body parts. When a computer looks at an ear, a knee, a toenail, what does it see? How does it describe bodies?
Last week, I started researching hand gestures in Italian Renaissance paintings because I was interested in knowing whether a computer vision algorithm trained on hand gestures would be able to interpret hand signals from art. I thought that if traditional gestural machine learning tools proved unhelpful, it would be an amazing exercise to train a neural net on the hand signals found in religious paintings.

One thought on “Project update: Algorithmic gaze.”