 For this week’s assignment, we were to use SVG graphics and data from Gapminder to create a simple data visualization.
For this week’s assignment, we were to use SVG graphics and data from Gapminder to create a simple data visualization.
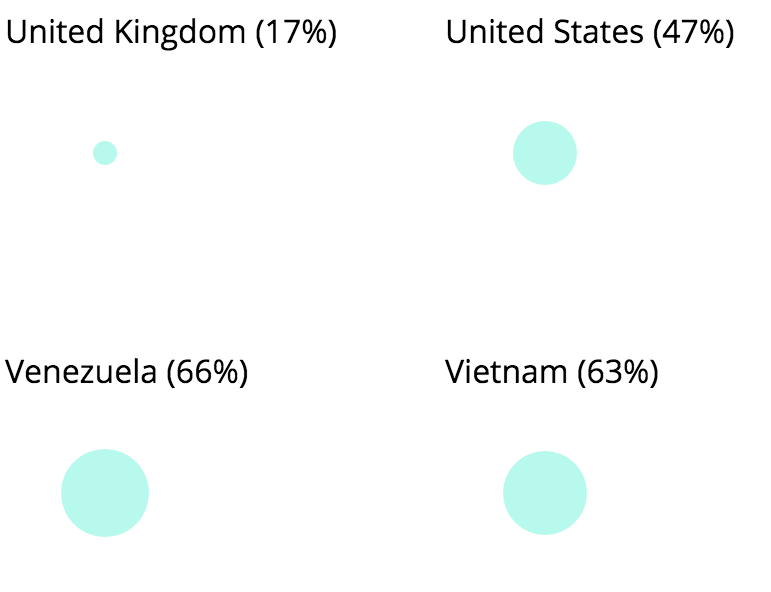
I created two simple data visualizations of this data set that shows, by country, private spend on health as a percentage of the total spending on health. Private health expenditure includes direct household (out-of-pocket) spending, private insurance, charitable donations, and direct service payments by private corporations.
The bubble chart
The first visualization was a bubble chart in which the size of each bubble corresponded to the percentage of the share (see it here). While I thought this method was visually compelling, I also felt that the information could be conveyed more accurately through a different visual. Instead of displaying the countries alphabetically, I thought it would be more informative to display them according to spend.
The bar chart
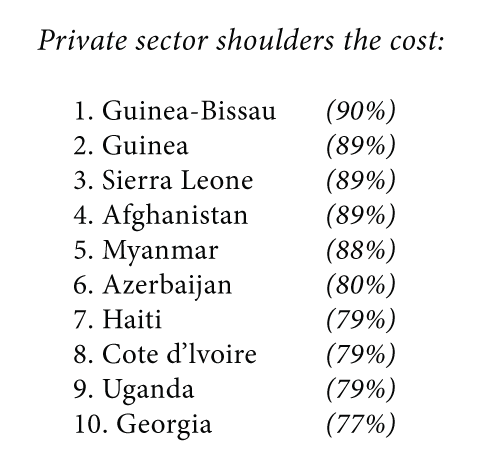
For the second visualization, I made a bar chart that showed the % private health spend for each country out of the total. I ordered the countries from those that had the highest private spending to the lowest. Check it out here.
Analysis
Visualizing this set of data gave me the ability to quickly compare private/public spend between countries and draw some conclusions.

You can check out my full GitHub repository here.
Other (unrelated) thoughts
We were also asked to respond to a graphic/chart/visual from the website Wait But Why, a popular resource for explaining complex subjects in a simple way. I decided to look at an article that explains the history of Iraq and ISIS. I studied Arabic language/Middle East Studies in college and my undergraduate thesis explored neo-tribalism in Saddam Hussein’s Iraq so I was curious to see if the author of the article got the history right.
I was surprised – the author did a very thorough job explaining the last 100 years in Iraqi history, with particular emphasis on the factors that led to the rise of ISIS. The Sykes-Picot agreement, which is responsible for diving up Iraq and much of the Middle East, is summarized pretty accurately in these two maps:
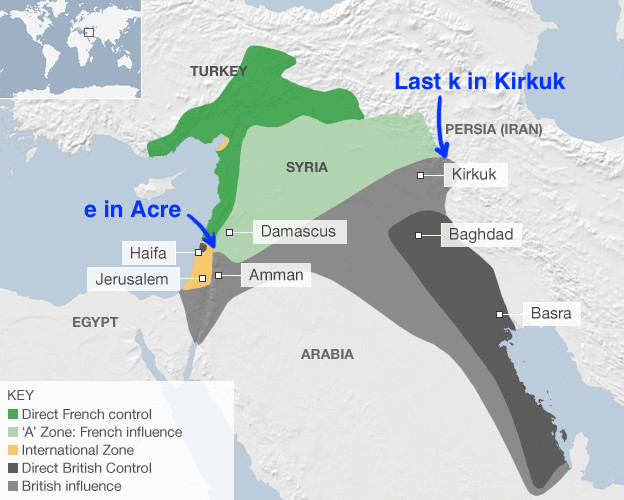
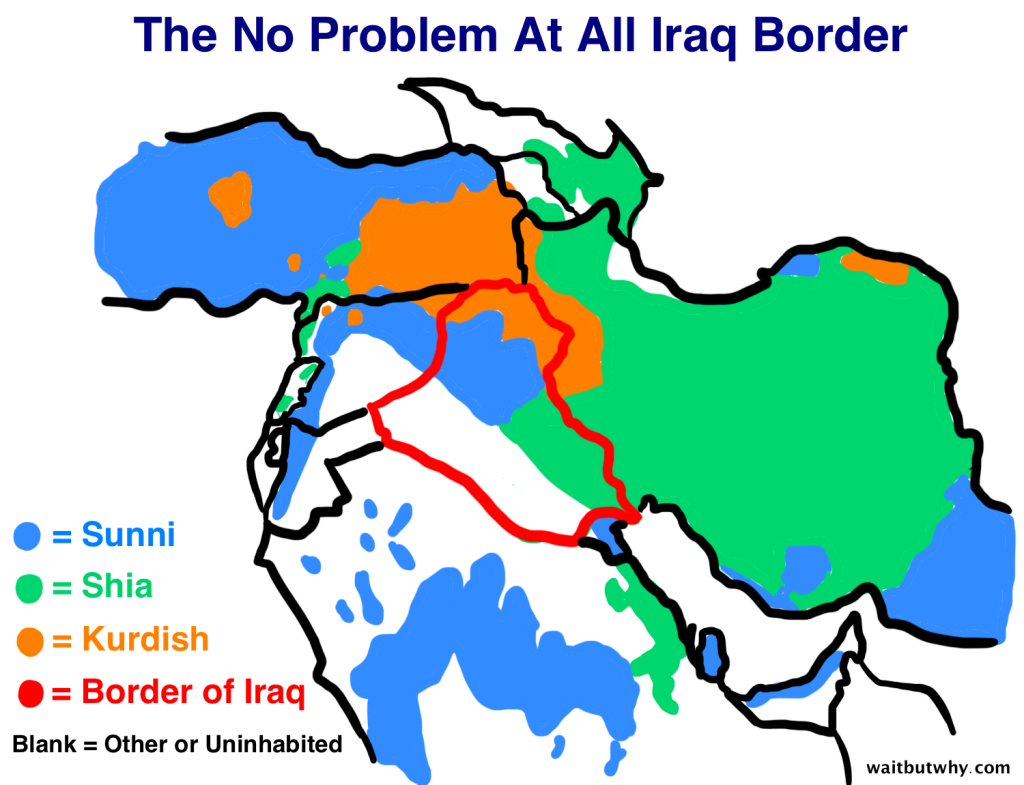
Source: Wait but why