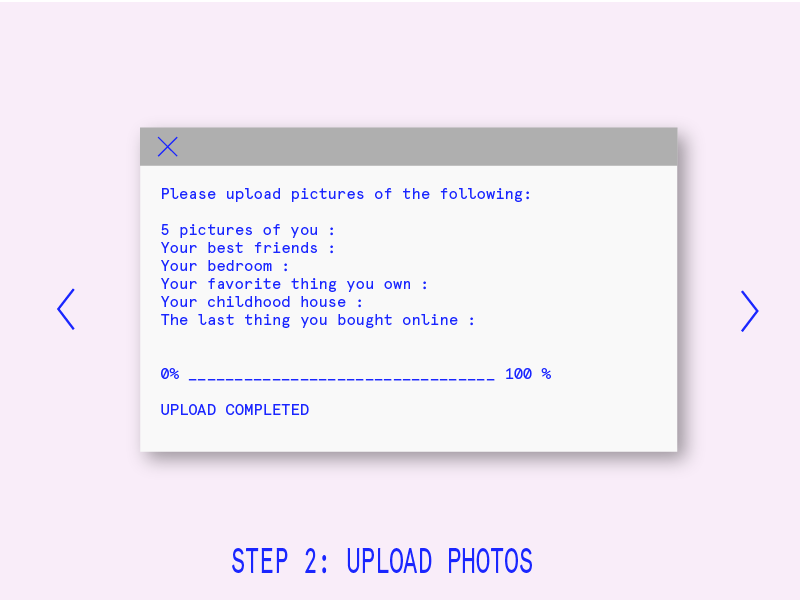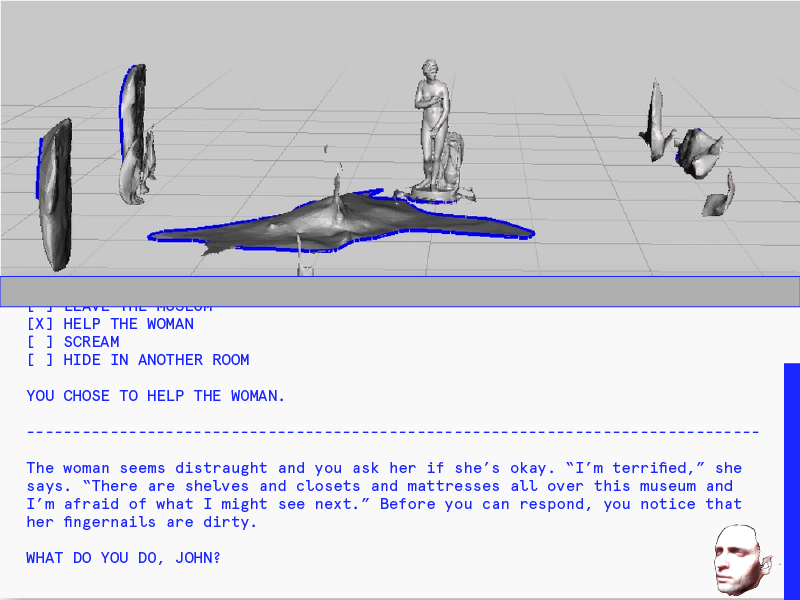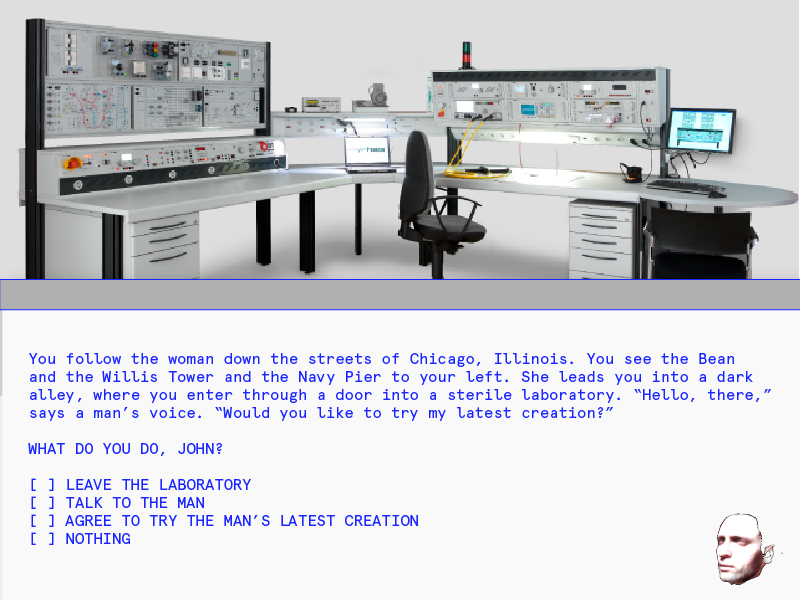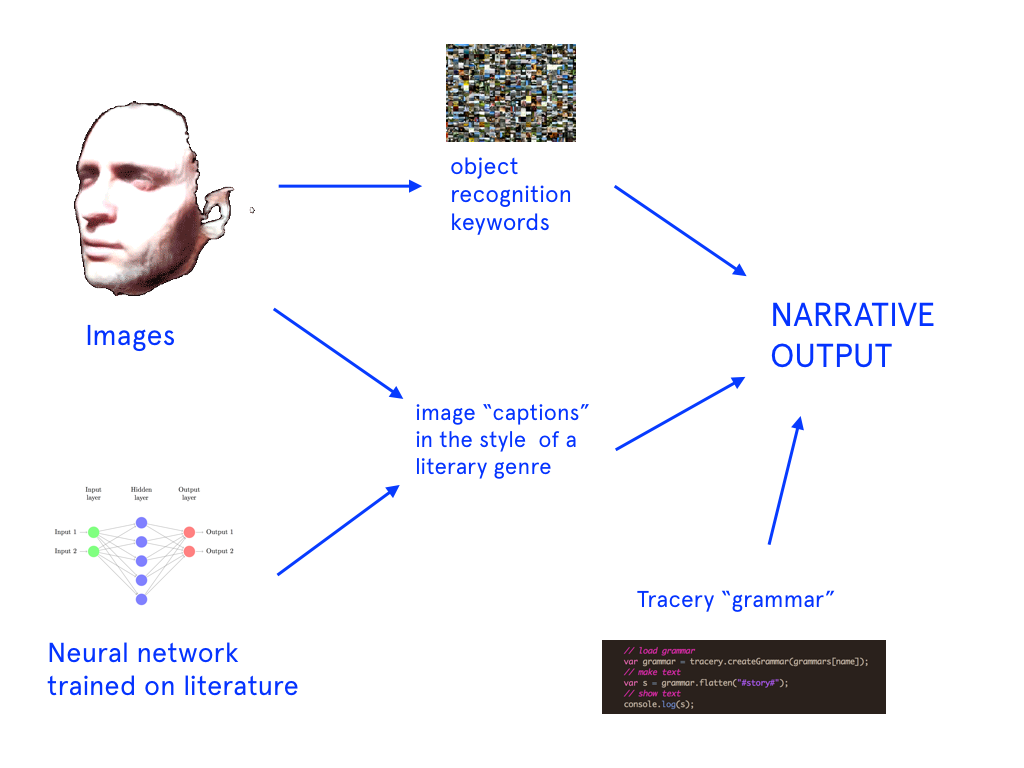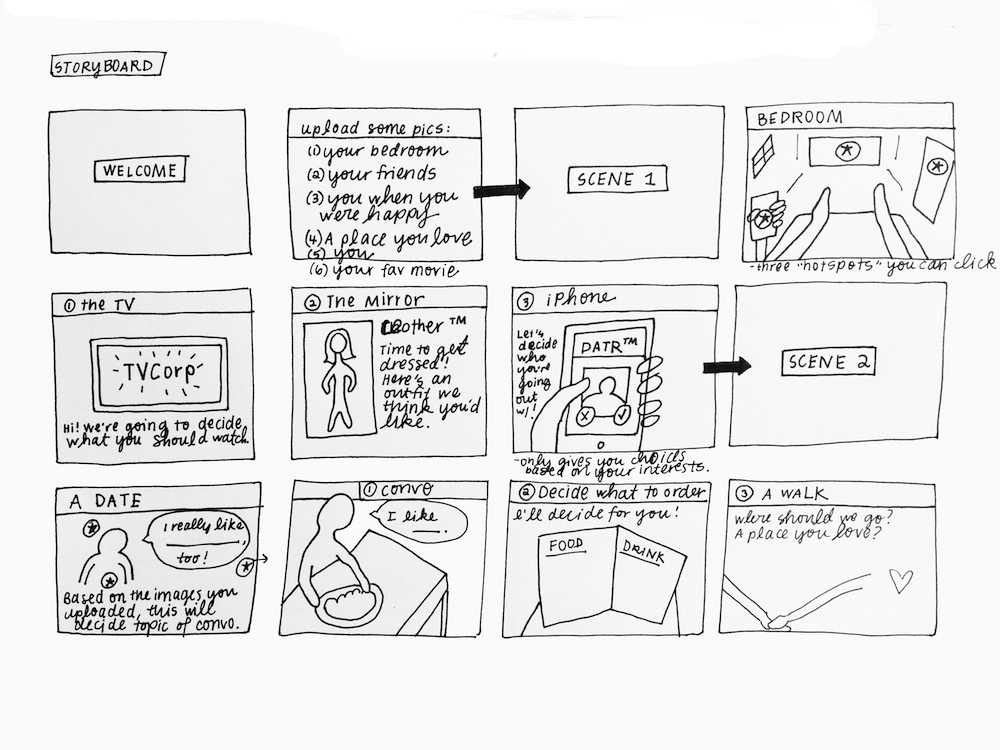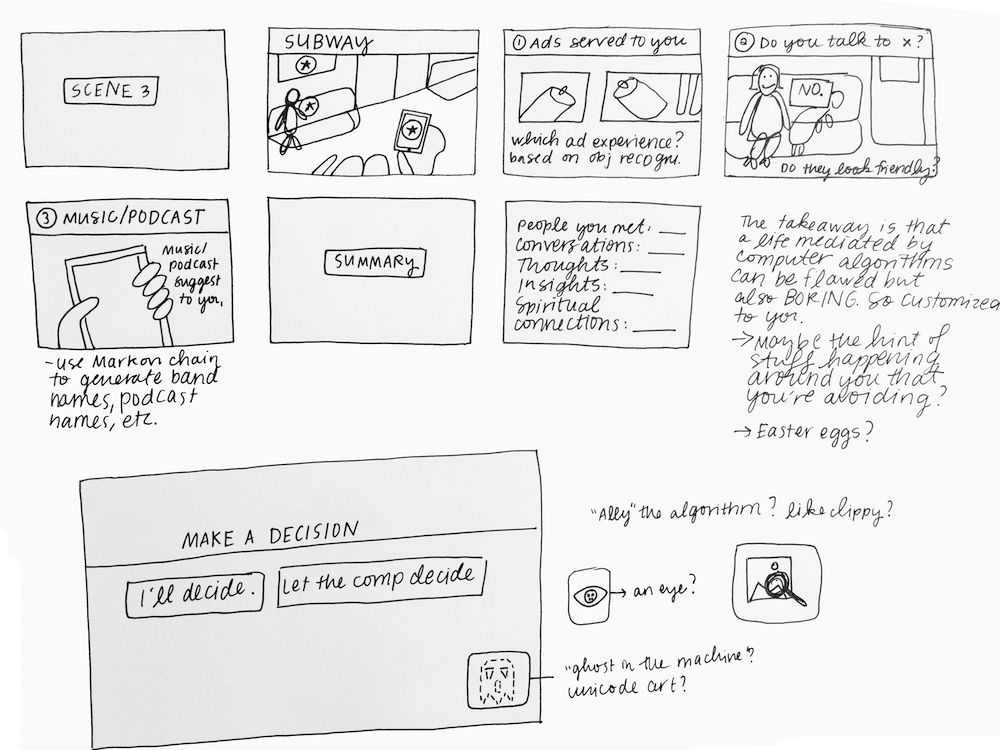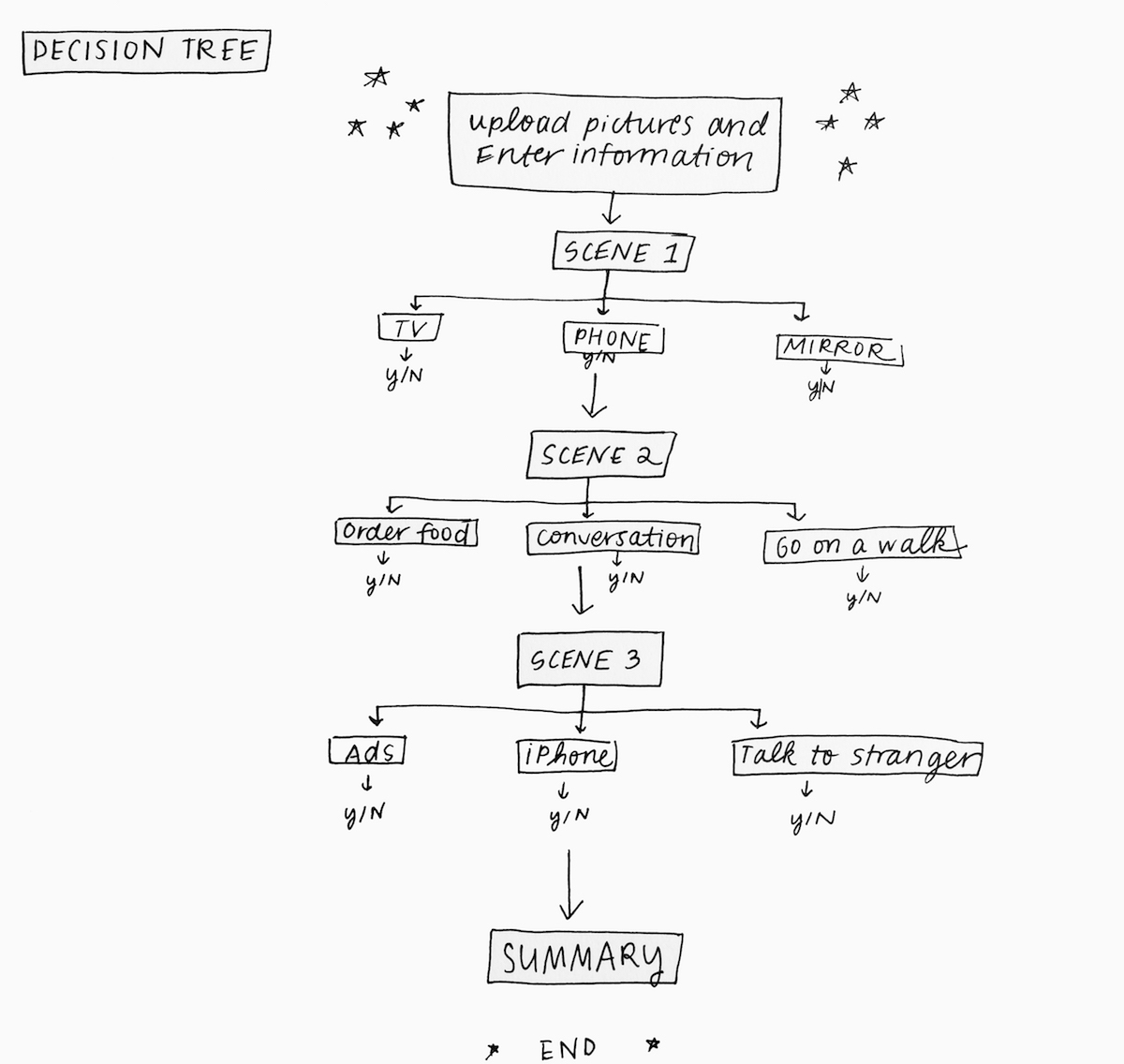
Last week I presented a handful of different design concepts for my project. The feedback from my classmates was actually very positive – while I feel that the project still lacks focus at this stage, their comments reaffirmed that the different iterations of this projects are all connected by a conceptual thread. My task in the coming weeks is to continue following that thread and consider each iteration of the project a creative intervention into the same set of questions.
Theory & conceptual framework.
We know that systems that are trained on datasets that contain biases may exhibit those biases when they’re used, thus digitizing cultural prejudices like institutional racism and classism. Researchers working in the field of computer vision operate in a liminal space, one in which the consequences of their work remain undefined by public policy. Very little work has been done on “computer vision as a critical technical practice that entangles aesthetics with politics and big data with bodies,” argues Jentery Sayers.

I want to explore the ways in which algorithmic authority exercises disciplinary power on the bodies it “sees” vis-a-vis computer vision. Last week I wrote about Lacan’s concept of the gaze, a scenario in which the subject of a viewer’s gaze internalizes his or her own subjectivization. Michel Foucault wrote in Discipline and Punish about how the gaze is employed in systems of power. I’ve written extensively about biopower and surveillance in previous blog posts (here and here), but I want to continue exploring how people regulate their behavior when they know a computer is watching. Whether real or not, the computer’s gaze has a self-regulating effect on the person who knows they are being looked at.
It’s important to remember that the processes involved in training a data set to recognize patterns in images are so tedious that we tend to automate them. In his paper “Computer Vision as a Public Act: On Digital Humanities and Algocracy”, Jentery Sayers suggests that computer vision algorithms represent a new kind of power called algocracy – rule of the algorithm. He argues that the “programmatic treatment of the physical world in digital form” is so deeply embedded in our modern infrastructure that these algorithms have begun shaping our behavior and assert authority over us. An excerpt from the paper’s abstract:
Computer vision is generally associated with the programmatic description and reconstruction of the physical world in digital form (Szeliski 2010: 3-10). It helps people construct and express visual patterns in data, such as patterns in image, video, and text repositories. The processes involved in this recognition are incredibly tedious, hence tendencies to automate them with algorithms. They are also increasingly common in everyday life, expanding the role of algorithms in the reproduction of culture.
From the perspective of economic sociology, A. Aneesh links such expansion to “a new kind of power” and governance, which he refers to as “algocracy—rule of the algorithm, or rule of the code” (Aneesh 2006: 5). Here, the programmatic treatment of the physical world in digital form is so significantly embedded in infrastructures that algorithms tacitly shape behaviors and prosaically assert authority in tandem with existing bureaucracies.
Routine decisions are delegated (knowingly or not) to computational procedures that—echoing the work of Alexander Galloway (2001), Wendy Chun (2011), and many others in media studies—run in the background as protocols or default settings.
For the purposes of this MLA panel, I am specifically interested in how humanities researchers may not only interpret computer vision as a public act but also intervene in it through a sort of “critical technical practice” (Agre 1997: 155) advocated by digital humanities scholars such as Tara McPherson (2012) and Alan Liu (2012).

I love these questions posed tacitly by pioneering CV researchers in the 1970s: How does computer vision differ from human vision? To what degree should computer vision be modeled on human phenomenology, and to what effects? Can computer or human vision even be modeled? That is, can either even be generalized? Where and when do issues of processing and memory matter most for recognition and description? And how should computer vision handle ambiguity? Now, the CV questions posed by Facebook and Apple are more along these lines: Is this you? Is this them?
The project.
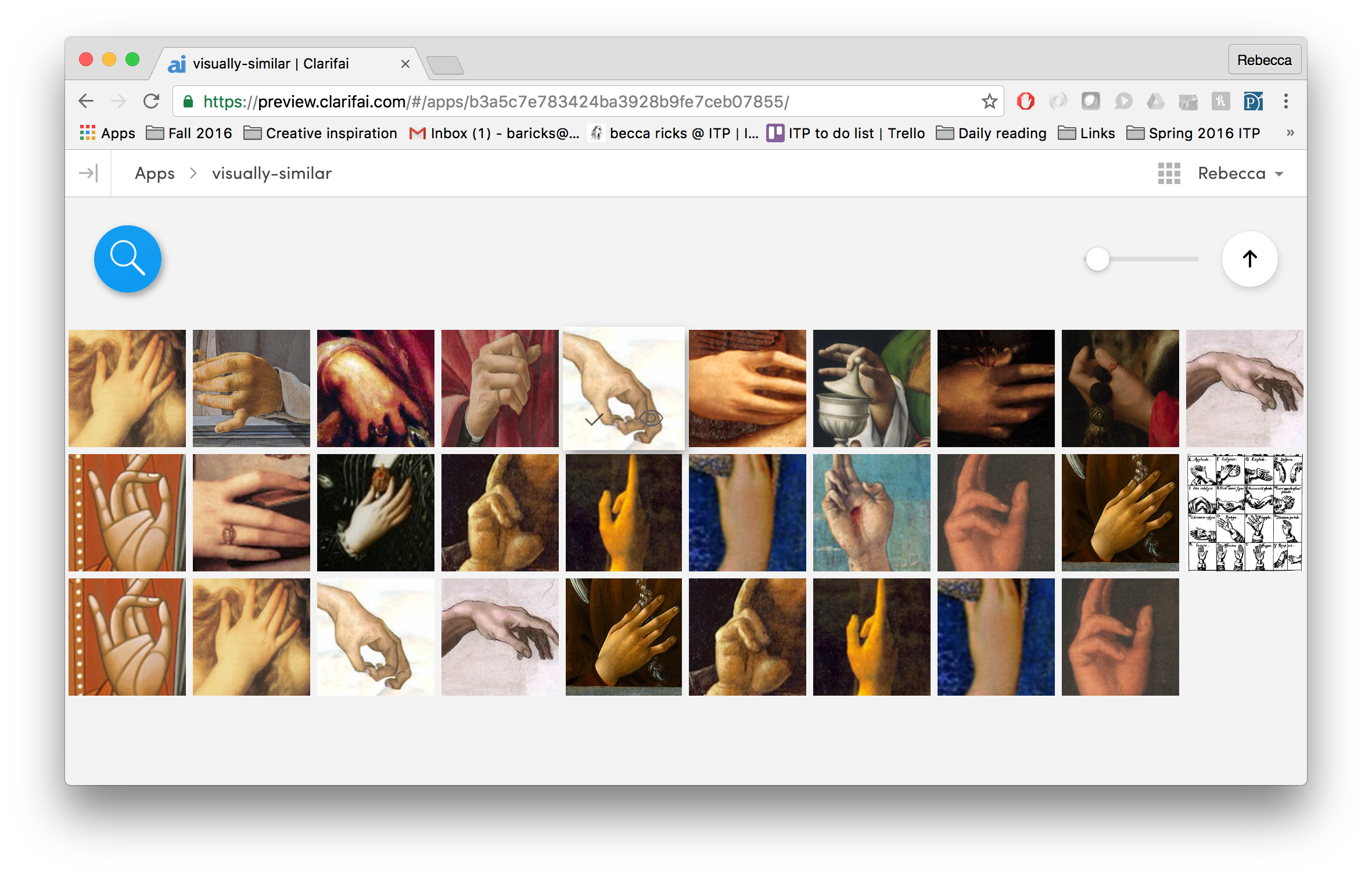
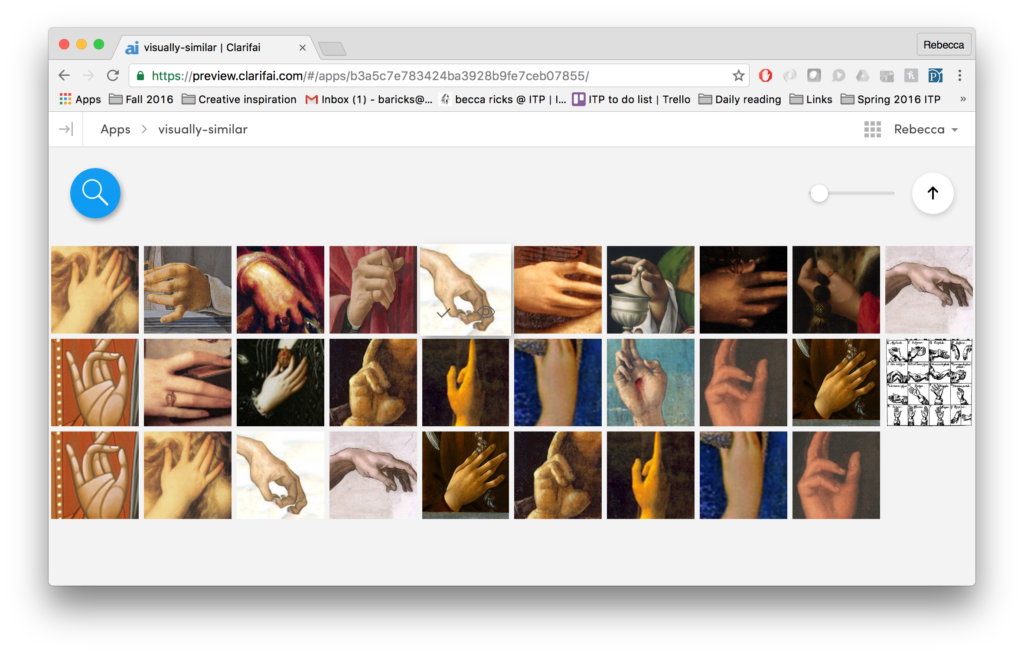
So how will these new ideas help me shape my project? For one, I’ve become much more wary of using pre-trained data sets like the Clarifai API or Microsoft’s COCO for image recognition. This week I built a Twitter bot that uses the Clarifai API to generate pithy descriptions of images tweeted at it.

I honestly was disappointed by the lack of specificity the data set offered. However, I’m excited that Clarifai announced today a new tool for users to train their own models for image classification.
I want to probe the boundaries of these pre-trained data sets – where do these tools break and why? How can I distort images in a way that objects are recognized as something other than themselves? What would happen if I trained my own data set on a gallery of images that I have curated? Computer vision isn’t source code; it’s a system of power.
For my project, I want to have control over the content that the model is being trained on so that it outputs interesting or surprising results. In terms of the aesthetic, I want to try out different visual ways of organizing these images – clusters, tile patterns, etc. Since training one of these models can take as little as a month, the goal for this week is to start creating the data set and the model.
I’ve been reading Wendy Chun’s Programmed Visions and Alexander Galloway’s Protocol: How Control Exists After Decentralization for months, but I’m recommitting to finishing these books in order to develop my project’s concept more fully.