This semester, I’ve focused my attention on creative ways of interpreting and visualizing my personal Facebook data.
I’m interested in exploring the concept of “digital dualism” – the habit of viewing the online and offline as largely distinct (source). We are actively constructing our identities whether behind a screen or in person. As Nathan Jurgenson writes, “Any zero-sum “on” and “offline” digital dualism betrays the reality of devices and bodies working together, always intersecting and overlapping, to construct, maintain, and destroy intimacy, pleasure, and other social bonds.”

With this project, I wanted to try re-inserting the digital world into the physical world. I decided to locate specific actions I took on Facebook within a physical geography and landscape.
It’s very easy to download your Facebook metadata from the website – all you have to do is follow these directions. In my data archive, I found information about every major administrative change I’ve made to my Facebook account since I created the account in 2006, including changes to my password, deactivating my account, changing my profile picture, etc. This information was interesting to me because from Facebook’s perspective, these activities were in all likelihood the most important decisions I had ever made as a Facebook user.
I rearranged that data into a simple JSON file:
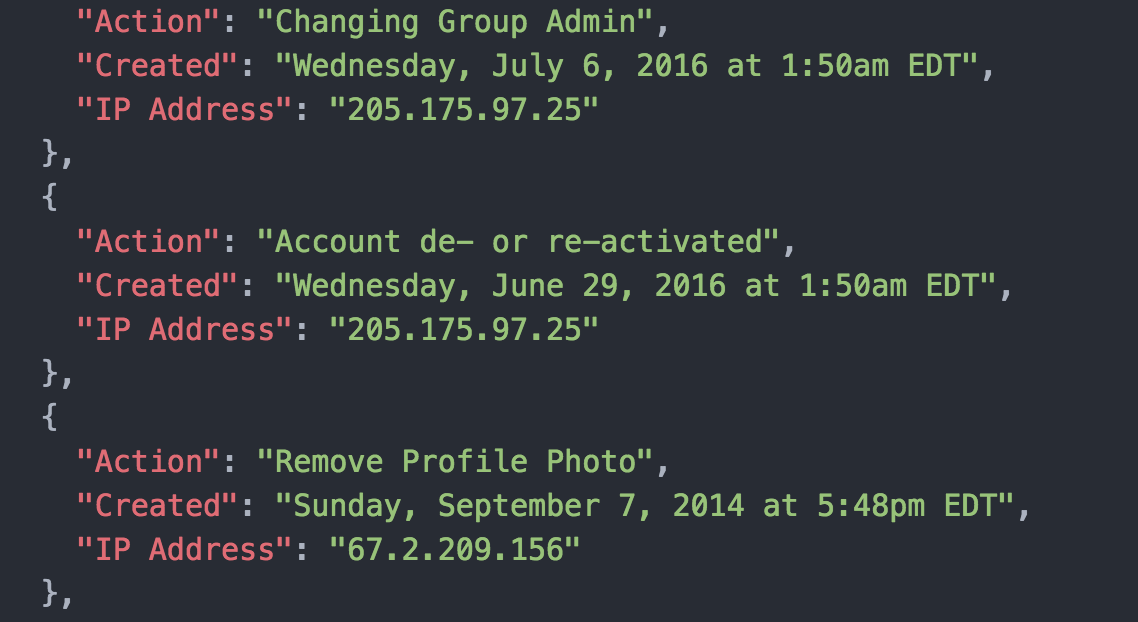
I decided to explore the IP Address metadata associated with each action. I wanted to know more about the physical location where I had made these decisions concerning my Facebook account, since I obviously didn’t remember where I was or what I was doing when I had made these changes.
I wrote a Python script (see code here) that performs several different actions for each item in the JSON file:
(1) Takes the IP address and finds the corresponding geolocation, including latitude & longitude & city/state;
(2) Feeds the latitude/longitude into Google Maps’ Street View and downloads 10 images that each rotate 5 degrees;
(3) Adds a caption to each image specifying the Facebook activity, the exact date/time, and the city/state; and
(4) Merges the 10 images into a gif.

The result was two dozen weird undulating gifs of Google Street View locations, which you can check out on the project website.

After doing all that work, however, I didn’t feel satisfied with the output. If the goal was to find a way to re-insert my digital data trail into a physical space, I felt that the goal hadn’t yet been realized in this form. I decided to take the project into a different, more spatially-minded direction.
I wrote another Python script that programmatically takes the IP address and searches for the latitude/longitude on Google Maps, clicks the 3D setting, records a short video of the three-dimensional landscape, and then exports the frames of that video into images.

Using the photogrammetry software Photoscan, I created a 3D mesh and texture from the video frames. Then, I made a quick design of the Facebook app on an iPhone with the specific Facebook activity associated with that location & IP address. Finally, I pulled the landscape .obj into Unity with the iPhone image and produced some strange, fantastical 3D landscapes: